
Wie kann ich aus einem Long-Datensatz Jahresmittelwerte berechnen, um zum Beispiel bestimmte Jahre oder Monate miteinander vergleichen zu können ? Ein Beispiel : Die Gas-Transparenzplattform AGSI der EU wertet einmal am Tag den Füllstand der Gasspeicher aus. Die Aufzeichnungen starten am 1.1.2011 - es liegen also tausende Datenpunkte vor, einer für jeden Tag.

Daraus möchte ich eine Auswertung erstellen, die mir mehrjährige Mittel- oder Min- und Max-Werte berechnet. Am Ende könnte man daraus zum Beispiel solch eine Grafik (wie die vom NDR) in Datawrapper basteln, die den jeweils aktuellen Jahresverlauf im Vergleich zu den Werten der anderen Jahre darstellt :

Den Datensatz kannst du von Github herunterladen oder direkt mit Pandas laden. Bei CSV-Dateien, die auf Github gehostet werden, ist es wichtig, dass man den “echt” Direktlink zur Datei findet. Manchmal muss man erst auf den Button “RAW” klicken, um dann die richtige URL kopieren zu können.
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/CHesseling/pandas-training/main/data/StorageData_GIE_2011-01-01_2023-01-01.csv', sep=';', parse_dates=['Gas Day Start'])
Wichtig ist, dass man “Gas Day Start” als Datentyp datetime lädt, ansonsten gibt es Fehler bei dem folgenden Schritt.
Tipp : Die Spaltennamen enthalten Leerzeichen und Großschreibung. Das kann zu Problemen führen. Mit Slugify kann man solche Spaltennamen vereinfachen
Unser Ziel ist eine Tabelle, die in den Zeilen vertikal die einzelnen Tage anzeigt, in den Spalten die Jahre und in den Zellen den Wert für den jeweiligen Tag des Jahres. Das geht mit der Pandas-Funktion pivot_table().
Damit wir später die Daten richtig pivotieren - also nach Jahren ordnen - können, müssen wir zwei Spalten hinzufügen : Eine mit dem jeweiligen Jahr. Eine weitere mit den Angaben für Tag und Monat. Das Problem dabei : Wenn man nur Tag und Monat als str extrahiert, gibt es häufig Probleme beim Sortieren. Deshalb muss man den Wert als Monat/Tag extrahieren :
df['month_day'] = df['Gas Day Start'].dt.strftime('%m.%d.')
df['year'] = df['Gas Day Start'].dt.strftime('%Y')
Als nächstes setzen wir das Datum als Index des Dataframes :
df.set_index('Gas Day Start', inplace=True)
Und nun können wir mit pivot_table() die Daten von einem Long-Datensatz in einen eher Wide(n)-Datensatz umbiegen. Der Befehl pivot_table() verlangt mehrere Argumente, unter anderem :
index: Was soll quasi vertikal in den Zeilenüberschriften stehen ?values: Was wollen wir zählen ? Was soll später in den Zellen stehen ?aggfunc: Wie sollen dievaluesaggregiert werden ? Als Summe ? Minimalwert ? Maximalwert ? Median ?columns(optional) : Sollen die Daten in Spalten aufgefächert werden ?
Wir wollen die Monat/Tag-Angaben in die Zeilen packen, die Jahre in die Spalten und den Füllstand Full (%) als Wert. Die Pivot-Funktion sieht dann so aus :
df_pivot = df.pivot_table(index='month_day', columns='year', values='Full (%)', aggfunc='max')
Wichtig ist es, auf den Unterschied zwischen df_pivot und df.pivot_table() zu auchten. Das erste ist ein Name für den neuen Dataframe, das zweite die Pandas-Funktion.
So sieht der fertige Dataframe aus :
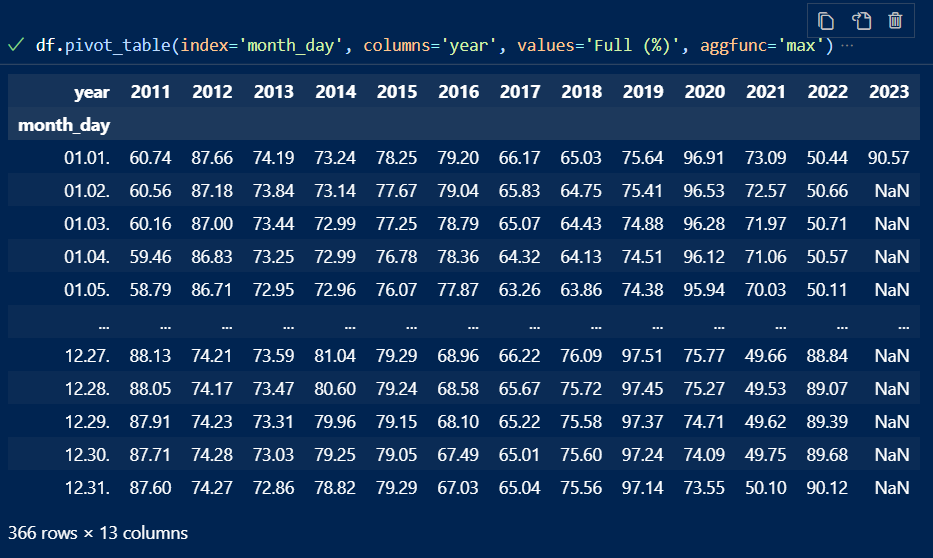
Was man hier nicht sieht : Es gibt natürlich ein Problem mit den Werten für die (Nicht-)Schaltjahre. Das kann man so sich anschauen :
df_pivot.loc['02.29.']

Es gibt keine feste Regel, wie man damit umgehen sollte. Aber natürlich sollte klar sein, dass Mittelwerte von diesem Tag natürlich problematisch sein könnten.
Mit dem Befehl iloc() können wir uns nun die Spalten von 2011-2021 slicen, um daraus die Mittelwerte, Minimalwerte und Maximalwerte zu berechnen :
df_slice = df_pivot.iloc[:,:-2]
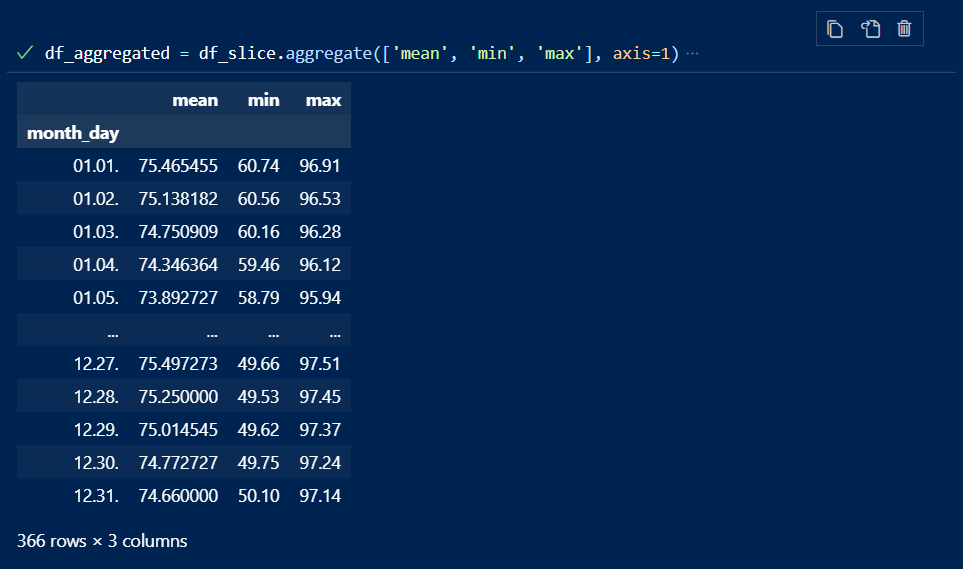
Jetzt lassen sich mit aggregate die Mittel-, Min- und Max-Werte berechnen :
df_aggregated = df_slice.aggregate(['mean', 'min', 'max'], axis=1)
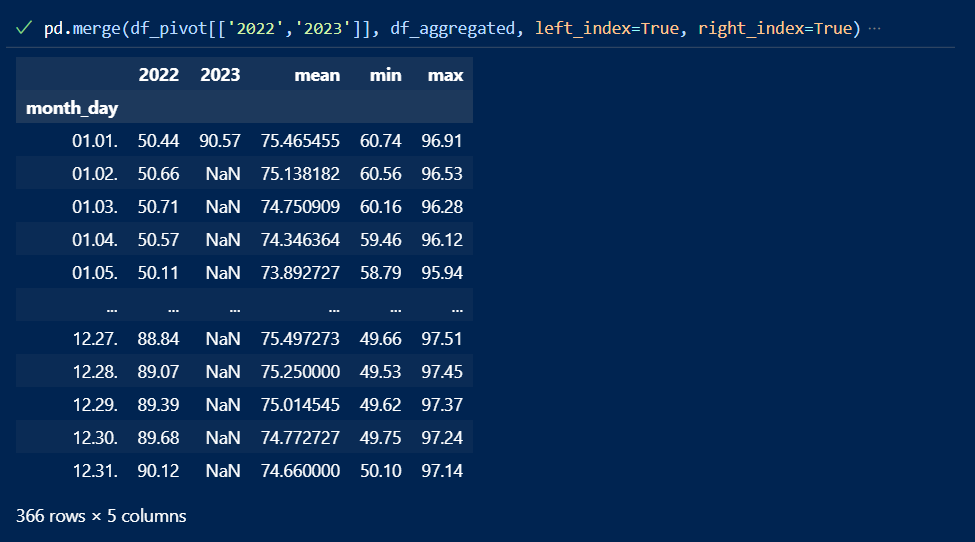
Und im letzten Schritt können wir jetzt die 2022er- und 2023er-Daten mit den Mittelwerten mergen :
df_komplett = pd.merge(df_pivot[['2022','2023']], df_aggregated, left_index=True, right_index=True)
Das Ergebnis sieht so aus :
Und zur visuellen Kontrolle kann man es fix plotten :
df_komplett.plot.line()
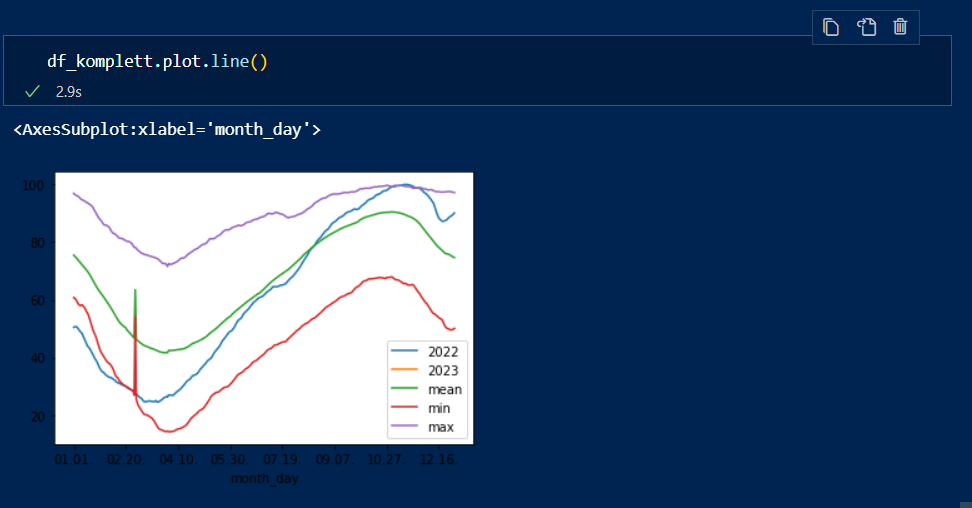
Der komische Peak ist natürlich der 29.2. - also würden wir den Wert in diesem Fall am besten rausnehmen.
Der Dataframe kann nun als CSV exportiert werden und z.B. in Datawrapper visualisiert werden.